
性能问题可分为以下两种类型之一:
- 在 CPU 上:线程花时间在 CPU 上运行的地方。
- CPU 外:在 I/O、锁、计时器、分页/交换等上阻塞时等待的时间。
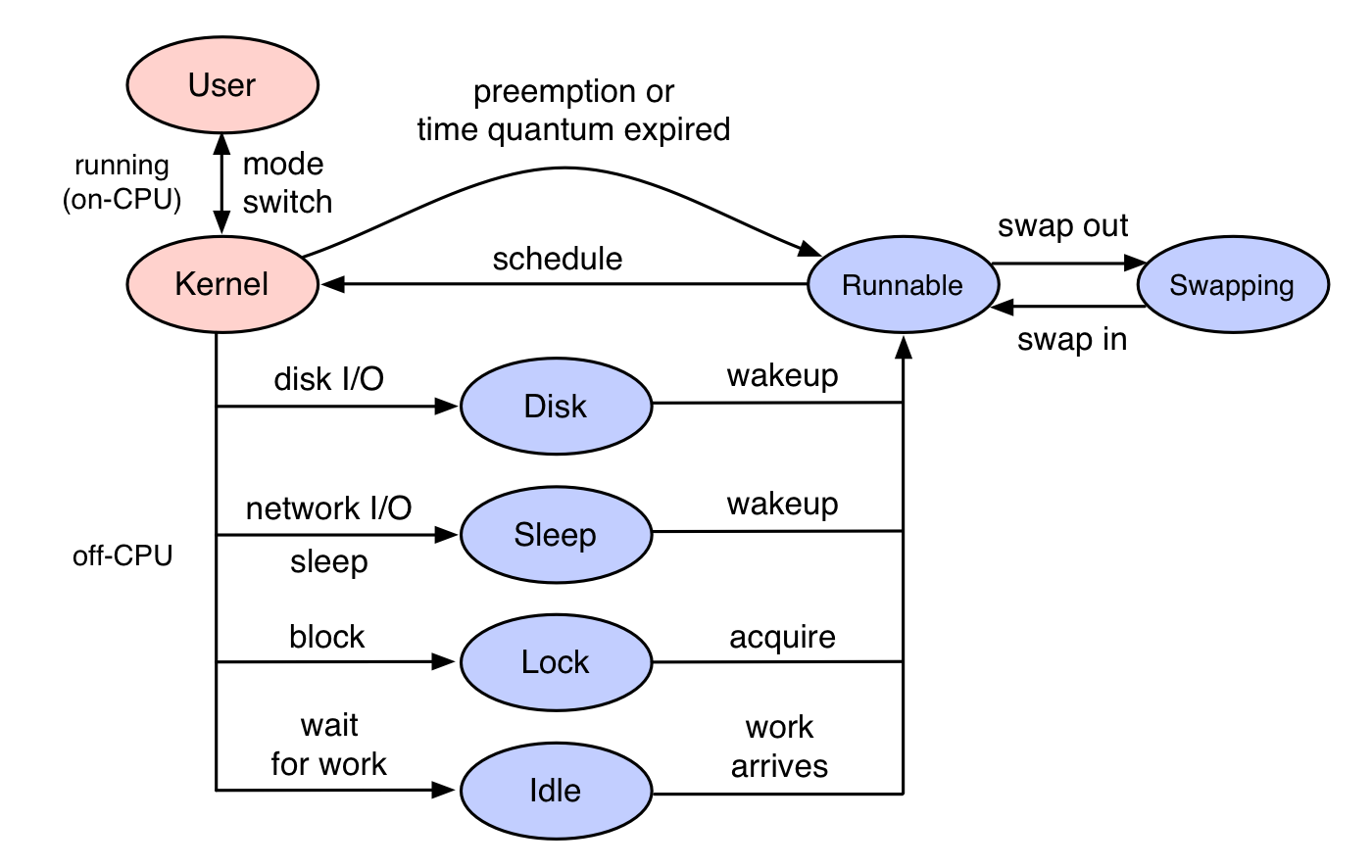
CPU 外分析是一种性能方法,用于测量和研究 CPU 外时间以及堆栈跟踪等上下文。它与 CPU 分析不同,后者仅在线程在 CPU 上执行时检查线程。此处,目标是被阻止和脱离 CPU 的线程状态,如右侧图中的蓝色所示。
CPU 外分析与 CPU 分析相辅相成,因此可以理解 100% 的线程时间。此方法也不同于检测通常阻塞的应用程序功能的跟踪技术,因为此方法针对内核调度程序的阻塞概念,这是一种方便的捕获概念。
线程可能出于多种原因离开 CPU,包括 I/O 和锁,但也有一些与当前线程的执行无关的原因,包括由于对 CPU 资源的高需求而导致的非自愿上下文切换和中断。无论出于何种原因,如果在工作负载请求(同步代码路径)期间发生这种情况,则会引入延迟。
在本页中,我将介绍 CPU 外时间作为指标,并总结 CPU 外分析的技术。 作为 CPU 外分析的示例实现,我将把它应用到 Linux,然后在后面的章节中总结其他操作系统。
目录
- 1. 先决条件
2.引言
3.开销
4.Linux
5.CPU 外时间
6.CPU 外分析
7.请求上下文
8.警告
9. 火焰图
10.唤醒
11.其他操作系统
12.起源
13.小结
14.更新
先决条件
CPU 外分析要求堆栈跟踪可供跟踪器使用,您可能需要首先修复此问题。许多应用程序都是使用 -fomit-frame-pointer gcc 选项编译的,从而打破了基于帧指针的堆栈遍历。VM 运行时(如动态的 Java 编译方法)和跟踪器在没有其他帮助的情况下可能无法找到其符号信息,从而导致堆栈跟踪仅为十六进制。还有其他陷阱。请参阅我之前关于修复堆栈跟踪和JIT 符号的性能的文章。
介绍
为了解释 CPU 外分析的作用,我将首先总结 CPU 采样和跟踪进行比较。然后,我将总结两种 CPU 外分析方法:跟踪和采样。虽然十多年来我一直在推广 CPU 外分析,但它仍然不是一种广泛使用的方法,部分原因是生产 Linux 环境中缺乏工具来衡量它。现在,随着eBPF和更新的Linux内核(4.8+)的出现,这种情况正在发生变化。
1. 中央处理器采样
许多传统的分析工具使用跨所有CPU的活动定时采样,以特定的时间间隔或速率(例如,99赫兹)收集当前指令地址(程序计数器)或整个堆栈回溯跟踪的快照。这将给出正在运行的函数或堆栈跟踪的计数,从而可以合理估计 CPU 周期的花费位置。在 Linux 上,采样模式下的性能工具(例如,-F 99)执行定时 CPU 采样。
考虑应用程序函数 A() 调用函数 B(),它进行阻塞系统调用:
CPU Sampling ----------------------------------------------->
| | | | | | | | | | | |
A A A A B B B B A A A A
A(---------. .----------)
| |
B(--------. .--)
| | user-land
- - - - - - - - - - syscall - - - - - - - - - - - - - - - - -
| | kernel
X Off-CPU |
block . . . . . interrupt
虽然这对于研究 CPU 上的问题(包括热代码路径和自适应互斥体旋转)非常有效,但当应用程序阻塞并等待 CPU 外时,它不会收集数据。
2. 应用程序跟踪
App Tracing ------------------------------------------------>
| | | |
A( B( B) A)
A(---------. .----------)
| |
B(--------. .--)
| | user-land
- - - - - - - - - - syscall - - - - - - - - - - - - - - - - -
| | kernel
X Off-CPU |
block . . . . . interrupt
在这里,对函数进行检测,以便在它们开始“(”和结束“)”时收集时间戳,以便可以计算在函数中花费的时间。如果时间戳包括经过的时间和 CPU 时间(例如,使用 times(2) 或 getrusage(2)),那么还可以计算哪些函数在 CPU 上很慢,哪些函数很慢,因为它们在 CPU 外被阻塞。与采样不同,这些时间戳可以具有非常高的分辨率(纳秒)。
虽然这有效,但缺点是,您要么跟踪所有应用程序功能,这可能会对性能产生重大影响(并影响您尝试测量的性能),要么选择可能阻止的功能,并希望您没有错过任何功能。
3. 非 CPU 跟踪
我将在这里总结这一点,然后在下一节中更详细地解释它。
Off-CPU Tracing -------------------------------------------->
| |
B B
A A
A(---------. .----------)
| |
B(--------. .--)
| | user-land
- - - - - - - - - - syscall - - - - - - - - - - - - - - - - -
| | kernel
X Off-CPU |
block . . . . . interrupt
使用此方法,仅跟踪将线程切换为 CPU 的内核函数,以及时间戳和用户空间堆栈跟踪。这侧重于 CPU 外事件,无需跟踪所有应用程序功能,也不需要知道应用程序是什么。这种方法适用于任何阻塞事件,任何应用程序:MySQL,Apache,Java等。
CPU 外跟踪捕获任何应用程序的所有等待事件。
在本页的后面部分,我将跟踪内核 CPU 外事件,并包括一些应用程序级检测来过滤掉异步等待时间(例如,等待工作的线程)。与应用程序级检测不同,我不需要寻找可能阻塞 CPU 外的每个位置;我只需要确定应用程序是否位于时间敏感的代码路径中(例如,在MySQL查询期间),以便延迟与工作负载同步。
CPU 外跟踪是我一直用于非 CPU 分析的主要方法。但也有抽样。
4. CPU 外采样
Off-CPU Sampling ------------------------------------------->
| | | | | | |
O O O O O O O
A(---------. .----------)
| |
B(--------. .--)
| | user-land
- - - - - - - - - - syscall - - - - - - - - - - - - - - - - -
| | kernel
X Off-CPU |
block . . . . . interrupt
此方法使用定时采样从未在 CPU 上运行的线程捕获阻塞的堆栈跟踪。它也可以通过挂机时间探查器来完成:一个始终对所有线程进行采样的探查器,无论它们是在 CPU 上还是在 CPU 外。然后可以过滤挂断时间配置文件输出,以仅查找 CPU 外堆栈。
系统概述很少使用非 CPU 采样。采样通常作为每 CPU 计时器中断实现,然后检查当前正在运行的中断进程:生成 CPU 上配置文件。非 CPU 采样器必须以不同的方式工作:在每个应用程序线程中设置计时器以唤醒它们并捕获堆栈,或者让内核按一定间隔遍历所有线程并捕获其堆栈。
开销
警告:对于 CPU 外跟踪,请注意调度程序事件可能非常频繁 - 在极端情况下,每秒数百万个事件 - 尽管跟踪器可能只为每个事件增加少量开销,但由于事件速率,开销可能会加起来并变得很重要。CPU 外采样也存在开销问题,因为系统可能有数万个线程必须不断采样,这比仅跨 CPU 计数的 CPU 采样开销高几个数量级。
要使用 CPU 外分析,您需要注意每一步的开销。将每个事件转储到用户空间进行后处理的跟踪器很容易变得令人望而却步,每分钟创建 GB 的跟踪数据。这些数据必须写入文件系统和存储设备并进行后处理,这会消耗更多的CPU。这就是为什么可以执行内核内摘要的跟踪器(如 Linux eBPF)对于减少开销和使 CPU 外分析变得实用如此重要。还要注意反馈循环:跟踪器跟踪由自身引起的事件。
如果我完全不知道使用新的调度程序跟踪器,我将首先仅跟踪十分之一秒(0.1 秒),然后从那里开始逐步提高,同时密切测量对系统 CPU 利用率、应用程序请求速率和应用程序延迟的影响。我还将考虑上下文切换的速率(例如,通过vmstat中的“cs”列测量),并且在速率较高的服务器上要更加小心。
为了让您了解开销,我测试了一个运行 Linux 4.15 的 8 CPU 系统,MySQL 负载很重,每秒导致 102k 上下文切换。服务器故意在 CPU 饱和(0% 空闲)下运行,因此任何跟踪器开销都会导致应用程序性能明显下降。然后,我将通过调度程序跟踪进行的 CPU 外分析与 Linux perf 和 eBPF 进行了比较,它们演示了不同的方法:用于事件转储的 perf 和用于内核内汇总的 eBPF:
- 使用 perf 跟踪每个计划程序事件会导致跟踪时的吞吐量下降 9%,在将 perf.data 捕获文件刷新到磁盘时偶尔会下降 12%。该文件在 10 秒的跟踪中最终达到 224 MB。然后通过运行 perf 脚本对文件进行后处理以执行符号转换,这会导致 13% 的性能下降(丢失 1 个 CPU)持续 35 秒。你可以总结这一点,说 10 秒的性能跟踪在 45 秒内花费了 9-13% 的开销。
- 相反,使用 eBPF 对内核上下文中的堆栈进行计数会导致 10 秒跟踪期间吞吐量下降 6%,从初始化 eBPF 时 1 秒下降 13% 开始,然后是 6 秒的后处理(已汇总堆栈的符号分辨率),成本下降 13%。因此,10 秒的跟踪会在 17 秒内花费 6-13% 的开销。好多了。
增加跟踪持续时间时会发生什么情况?对于 eBPF,它只是捕获和转换唯一的堆栈,不会随跟踪持续时间线性扩展。我通过将跟踪从 10 秒增加到 60 秒来测试这一点,这只会将 eBPF 后处理从 6 秒增加到 7 秒。与 perf 相同,将其后处理时间从 35 秒增加到 212 秒,因为它需要处理 6 倍的数据量。为了完全理解这一点,值得注意的是,后处理是一项用户级活动,可以对其进行调整以减少对生产工作负载的干扰,例如通过使用不同的计划程序优先级。想象一下,对于此活动,将 CPU 上限为 10%(一个 CPU):性能损失可能可以忽略不计,然后 eBPF 后处理阶段可能需要 70 秒——还不错。但是,perf 脚本时间可能需要 2120 秒(35 分钟),这将使调查停止。性能的开销不仅仅是 CPU,还有磁盘 I/O。
此 MySQL 示例与生产工作负载相比如何?它每秒进行 102k 上下文切换,这是相对较高的:我目前看到的许多生产系统都在 20-50k/s 范围内。这表明这里描述的开销比我在这些生产系统上看到的要高出大约 2 倍。但是,MySQL 堆栈深度相对较轻,通常只有 20-40 帧,而生产应用程序可以超过 100 帧。这也很重要,可能意味着我的MySQL堆栈开销可能只是我在生产中看到的一半。因此,这可能会平衡我的生产系统。
Linux: perf, eBPF
CPU 外分析是一种通用方法,应该适用于任何操作系统。我将演示如何使用 CPU 外跟踪在 Linux 上执行此操作,然后在后面的部分中总结其他操作系统。
Linux 上有许多跟踪器可用于 CPU 外分析。我将在这里使用eBPF,因为它可以轻松地对堆栈跟踪和时间进行内核内摘要。eBPF是Linux内核的一部分,我将通过bcc前端工具使用它。这些至少需要 Linux 4.8 才能支持堆栈跟踪。
你可能想知道我在 eBPF 之前是如何进行 CPU 外分析的。许多不同的方法,包括每种阻塞类型的完全不同的方法:存储 I/O 的存储跟踪、调度程序延迟的内核统计信息等。为了实际进行 CPU 外分析,我之前使用了 SystemTap 和perf事件日志记录 - 尽管这有更高的开销(我在perf_events CPU 外时间火焰图中写过)。有一次,我写了一个名为proc-profiler.pl 的简单的挂机时间内核堆栈分析器,它对给定PID的/proc/PID/stack进行了采样。它工作得很好。我也不是第一个破解这种墙上时间剖析器的人,请参阅poormans剖面器和Tanel Poder的快速'n'脏故障排除。
非 CPU 时间
这是线程在 CPU 外等待所花费的时间(阻塞时间),而不是在 CPU 上运行所花费的时间。它可以作为持续时间内的总计进行度量(已由 /proc 统计信息提供),也可以针对每个阻塞事件进行度量(通常需要跟踪器)。
首先,我将展示您可能已经熟悉的工具的总 CPU 外时间。time(1) 命令。例如,定时焦油(1):
$ time tar cf archive.tar linux-4.15-rc2
real 0m50.798s
user 0m1.048s
sys 0m11.627s
tar 运行大约需要一分钟,但 time 命令显示它只花费了 1.0 秒的用户模式 CPU 时间和 11.6 秒的内核模式 CPU 时间,总共运行了 50.8 秒的时间。我们错过了 38.2 秒!那是 tar 命令在 CPU 之外被阻止的时候,毫无疑问,将存储 I/O 作为其归档生成的一部分。
要更详细地检查 CPU 外时间,可以使用内核调度程序函数的动态跟踪或使用调度跟踪点的静态跟踪。bcc/eBPF项目包括由Sasha Goldshtein开发的cpudist,它具有-O模式来测量CPU外时间。这需要 Linux 4.4 或更高版本。测量 tar 的 CPU 外时间:
# /usr/share/bcc/tools/cpudist -O -p `pgrep -nx tar`
Tracing off-CPU time... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 3 | |
2 -> 3 : 50 | |
4 -> 7 : 289 | |
8 -> 15 : 342 | |
16 -> 31 : 517 | |
32 -> 63 : 5862 |*** |
64 -> 127 : 30135 |**************** |
128 -> 255 : 71618 |****************************************|
256 -> 511 : 37862 |********************* |
512 -> 1023 : 2351 |* |
1024 -> 2047 : 167 | |
2048 -> 4095 : 134 | |
4096 -> 8191 : 178 | |
8192 -> 16383 : 214 | |
16384 -> 32767 : 33 | |
32768 -> 65535 : 8 | |
65536 -> 131071 : 9 | |
这表明大多数阻塞事件在 64 到 511 微秒之间,这与闪存 I/O 延迟一致(这是一个基于闪存的系统)。跟踪时,最慢的阻塞事件达到 65 到 131 毫秒的范围(此直方图中的最后一个存储桶)。
这个 CPU 外时间由什么组成?从线程阻塞到再次开始运行的所有内容,包括调度程序延迟。
在撰写本文时,cpudist 使用 kprobes(内核动态跟踪)来检测 finish_task_switch() 内核函数。(出于 API 稳定性原因,它应该使用调度跟踪点,但第一次尝试没有成功,目前已还原。
finish_task_switch() 的原型是:
static struct rq *finish_task_switch(struct task_struct *prev)
为了让您了解此工具的工作原理:finish_task_switch() 函数在下一个运行的线程的上下文中调用。eBPF 程序可以使用 kprobes 检测此函数和参数,获取当前 PID(通过 bpf_get_current_pid_tgid()),还可以获取高分辨率时间戳 (bpf_ktime_get_ns())。这是上述摘要所需的所有信息,该摘要使用 eBPF 映射在内核上下文中有效地存储直方图存储桶。这是cpudist 的完整来源。
eBPF并不是Linux上唯一用于测量CPU外时间的工具。perf工具在其perf 调度 timehist输出中提供了一个“等待时间”列,该列不包括计划程序时间,因为它单独显示在相邻列中。该输出显示每个调度程序事件的等待时间,并且比 eBPF 直方图摘要需要更多的开销来衡量。
将 CPU 外时间测量为直方图有点用,但不是很多。我们真正想知道的是上下文 - 为什么线程阻塞并离开CPU。这是 CPU 外分析的重点。
非 CPU 分析
CPU 外分析是分析非 CPU 时间以及堆栈跟踪以确定线程阻塞原因的方法。由于以下原理,CPU 外跟踪分析技术可以轻松实现:
应用程序堆栈跟踪在 CPU 外时不会更改。
这意味着我们只需要在 CPU 离线周期的开始或结束时测量一次堆栈跟踪。结束通常更容易,因为无论如何您都在记录时间间隔。以下是使用堆栈跟踪来测量 CPU 外时间的跟踪伪代码:
on context switch finish:
sleeptime[prev_thread_id] = timestamp
if !sleeptime[thread_id]
return
delta = timestamp - sleeptime[thread_id]
totaltime[pid, execname, user stack, kernel stack] += delta
sleeptime[thread_id] = 0
on tracer exit:
for each key in totaltime:
print key
print totaltime[key]
关于这一点的一些注意事项:所有测量都从一个检测点发生,即上下文切换例程的末尾,这是在下一个线程(例如,Linux finish_task_switch() 函数)的上下文中。这样,我们可以通过简单地获取当前上下文(pid、execname、用户堆栈、内核堆栈)来计算 CPU 外持续时间,同时检索该持续时间的上下文,跟踪器使这变得容易。
这就是我的offcputime bcc / eBPF程序所做的,它至少需要Linux 4.8才能工作。我将演示如何使用 bcc/eBPF offcputime 来测量 tar 程序的阻塞堆栈。我将它限制为内核堆栈,仅以 (-K) 开头:
# /usr/share/bcc/tools/offcputime -K -p `pgrep -nx tar`
Tracing off-CPU time (us) of PID 15342 by kernel stack... Hit Ctrl-C to end.
^C
[...]
finish_task_switch
__schedule
schedule
schedule_timeout
__down
down
xfs_buf_lock
_xfs_buf_find
xfs_buf_get_map
xfs_buf_read_map
xfs_trans_read_buf_map
xfs_da_read_buf
xfs_dir3_block_read
xfs_dir2_block_getdents
xfs_readdir
iterate_dir
SyS_getdents
entry_SYSCALL_64_fastpath
- tar (18235)
203075
finish_task_switch
__schedule
schedule
schedule_timeout
wait_for_completion
xfs_buf_submit_wait
xfs_buf_read_map
xfs_trans_read_buf_map
xfs_imap_to_bp
xfs_iread
xfs_iget
xfs_lookup
xfs_vn_lookup
lookup_slow
walk_component
path_lookupat
filename_lookup
vfs_statx
SYSC_newfstatat
entry_SYSCALL_64_fastpath
- tar (18235)
661626
finish_task_switch
__schedule
schedule
io_schedule
generic_file_read_iter
xfs_file_buffered_aio_read
xfs_file_read_iter
__vfs_read
vfs_read
SyS_read
entry_SYSCALL_64_fastpath
- tar (18235)
18413238
我已将输出截断到最后三个堆栈。最后一个,显示总共 18.4 秒的 CPU 外时间,在读取系统调用路径中以 io_schedule() 结尾 – 这是 tar 读取文件内容,并在磁盘 I/O 上阻塞。它上面的堆栈在统计系统调用中显示 662 毫秒,最终也会通过 xfs_buf_submit_wait() 等待存储 I/O。顶部堆栈总共为 203 毫秒,在执行 getdents 系统调用(目录列表)时似乎在锁上显示 tar 阻塞。
解释这些堆栈跟踪需要稍微熟悉源代码,这取决于应用程序的复杂程度及其语言。你这样做的次数越多,你就会变得越快,因为你会识别相同的函数和堆栈。
我现在将包括用户级堆栈:
# /usr/share/bcc/tools/offcputime -p `pgrep -nx tar`
Tracing off-CPU time (us) of PID 18311 by user + kernel stack... Hit Ctrl-C to end.
[...]
finish_task_switch
__schedule
schedule
io_schedule
generic_file_read_iter
xfs_file_buffered_aio_read
xfs_file_read_iter
__vfs_read
vfs_read
SyS_read
entry_SYSCALL_64_fastpath
[unknown]
- tar.orig (30899)
9125783
这不起作用:用户级堆栈只是“[未知]”。原因是默认版本的tar是在没有帧指针的情况下编译的,而这个版本的bcc/eBPF需要它们来遍历堆栈跟踪。我想展示这个陷阱的样子,以防你也击中它。
我确实修复了tar的堆栈(请参阅前面的先决条件)以查看它们的外观:
# /usr/share/bcc/tools/offcputime -p `pgrep -nx tar`
Tracing off-CPU time (us) of PID 18375 by user + kernel stack... Hit Ctrl-C to end.
[...]
finish_task_switch
__schedule
schedule
io_schedule
generic_file_read_iter
xfs_file_buffered_aio_read
xfs_file_read_iter
__vfs_read
vfs_read
SyS_read
entry_SYSCALL_64_fastpath
__read_nocancel
dump_file0
dump_file
dump_dir0
dump_dir
dump_file0
dump_file
dump_dir0
dump_dir
dump_file0
dump_file
dump_dir0
dump_dir
dump_file0
dump_file
create_archive
main
__libc_start_main
[unknown]
- tar (15113)
426525
[...]
好的,所以看起来tar对文件系统树有一个递归的步行算法。
这些堆栈跟踪很棒 - 它显示了应用程序阻塞和等待 CPU 之外的原因,以及多长时间。这正是我通常寻找的信息。但是,阻塞堆栈跟踪并不总是那么有趣,因为有时您需要查找请求同步上下文。
请求同步上下文
等待工作的应用程序(例如在套接字上等待线程池的 Web 服务器)对 CPU 外分析提出了挑战:通常大部分阻塞时间将在堆栈中等待工作,而不是执行工作。这会用不太有趣的堆栈淹没输出。
作为这种现象的一个例子,这里是MySQL服务器进程的CPU外堆栈,它什么都不做。每秒零请求数:
# /usr/share/bcc/tools/offcputime -p `pgrep -nx mysqld`
Tracing off-CPU time (us) of PID 29887 by user + kernel stack... Hit Ctrl-C to end.
^C
[...]
finish_task_switch
__schedule
schedule
do_nanosleep
hrtimer_nanosleep
sys_nanosleep
entry_SYSCALL_64_fastpath
__GI___nanosleep
srv_master_thread
start_thread
- mysqld (29908)
3000333
finish_task_switch
__schedule
schedule
futex_wait_queue_me
futex_wait
do_futex
sys_futex
entry_SYSCALL_64_fastpath
pthread_cond_timedwait@@GLIBC_2.3.2
os_event::wait_time_low(unsigned long, long)
srv_error_monitor_thread
start_thread
- mysqld (29906)
3000342
finish_task_switch
__schedule
schedule
read_events
do_io_getevents
SyS_io_getevents
entry_SYSCALL_64_fastpath
[unknown]
LinuxAIOHandler::poll(fil_node_t**, void**, IORequest*)
os_aio_handler(unsigned long, fil_node_t**, void**, IORequest*)
fil_aio_wait(unsigned long)
io_handler_thread
start_thread
- mysqld (29896)
3500863
[...]
Various threads are polling for work and other background tasks. These background stacks can dominate the output, even for a busy MySQL server. What I'm usually looking for is off-CPU time during a database query or command. That's the time that matters – the time that's hurting the end customer. To find those in the output, I need to hunt around for stacks in query context.
For example, now from a busy MySQL server:
# /usr/share/bcc/tools/offcputime -p `pgrep -nx mysqld`
Tracing off-CPU time (us) of PID 29887 by user + kernel stack... Hit Ctrl-C to end.
^C
[...]
finish_task_switch
__schedule
schedule
io_schedule
wait_on_page_bit_common
__filemap_fdatawait_range
file_write_and_wait_range
ext4_sync_file
do_fsync
SyS_fsync
entry_SYSCALL_64_fastpath
fsync
log_write_up_to(unsigned long, bool)
trx_commit_complete_for_mysql(trx_t*)
[unknown]
ha_commit_low(THD*, bool, bool)
TC_LOG_DUMMY::commit(THD*, bool)
ha_commit_trans(THD*, bool, bool)
trans_commit_stmt(THD*)
mysql_execute_command(THD*, bool)
mysql_parse(THD*, Parser_state*)
dispatch_command(THD*, COM_DATA const*, enum_server_command)
do_command(THD*)
handle_connection
pfs_spawn_thread
start_thread
- mysqld (13735)
1086119
[...]
This stack identifies some time (latency) during a query. The do_command() -> mysql_execute_command() code path is a give away. I know this because I'm familiar with the code from all parts of this stack: MySQL and kernel internals.
您可以想象编写一个简单的文本后处理器,它根据一些特定于应用程序的模式匹配来提取感兴趣的堆栈。这可能工作正常。还有另一种方法,效率更高一些,尽管还需要应用程序细节:扩展跟踪程序以检测应用程序请求(在此MySQL服务器示例中为do_command()函数),然后仅在应用程序请求期间发生时记录CPU外时间。我以前做过,它可以提供帮助。
警告
最大的警告是 CPU 外分析的开销,如前面的开销部分所述,然后是使堆栈跟踪正常工作,我在前面的先决条件部分中对此进行了总结。还有需要注意的调度程序延迟和非自愿上下文切换,我将在这里总结,以及我将在后面的部分中讨论的唤醒堆栈。
调度程序延迟
这些堆栈中缺少的是,CPU 外时间是否包括等待 CPU 运行队列所花费的时间。此时间称为调度程序延迟、运行队列延迟或调度程序队列延迟。如果 CPU 以饱和状态运行,则每当线程阻塞时,它可能会在唤醒后等待轮到 CPU 的额外时间。该时间将包含在 CPU 外时间中。
您可以使用额外的跟踪事件将 CPU 外时间划分为时间阻塞与调度程序延迟,但实际上,CPU 饱和很容易发现,因此当您有已知的 CPU 饱和问题需要处理时,您不太可能花费大量时间研究 CPU 外时间。
非自愿上下文切换
如果您看到没有意义的用户级堆栈跟踪 - 没有理由阻止和离开CPU - 这可能是由于非自愿上下文切换。这通常发生在 CPU 饱和时,内核 CPU 调度程序让线程打开 CPU,然后在它们到达其时间片时启动它们。线程可以随时启动,例如在 CPU 繁重的代码路径中间,并且生成的 CPU 外堆栈跟踪毫无意义。
下面是来自 offcputime 的示例堆栈,它可能是非自愿的上下文切换:
# /usr/share/bcc/tools/offcputime -p `pgrep -nx mysqld`
Tracing off-CPU time (us) of PID 29887 by user + kernel stack... Hit Ctrl-C to end.
[...]
finish_task_switch
__schedule
schedule
exit_to_usermode_loop
prepare_exit_to_usermode
swapgs_restore_regs_and_return_to_usermode
Item_func::type() const
JOIN::make_join_plan()
JOIN::optimize()
st_select_lex::optimize(THD*)
handle_query(THD*, LEX*, Query_result*, unsigned long long, unsigned long long)
[unknown]
mysql_execute_command(THD*, bool)
Prepared_statement::execute(String*, bool)
Prepared_statement::execute_loop(String*, bool, unsigned char*, unsigned char*)
mysqld_stmt_execute(THD*, unsigned long, unsigned long, unsigned char*, unsigned long)
dispatch_command(THD*, COM_DATA const*, enum_server_command)
do_command(THD*)
handle_connection
pfs_spawn_thread
start_thread
- mysqld (30022)
13
[...]
目前尚不清楚(基于函数名称)为什么这个线程在 Item_func::type() 中被阻塞。我怀疑这是一个非自愿的上下文切换,因为服务器已 CPU 饱和。
offcputime 的解决方法是筛选TASK_UNINTERRUPTIBLE状态 (2):
# /usr/share/bcc/tools/offcputime -p `pgrep -nx mysqld` --state 2
在 Linux 上,状态 TASK_RUNNING (0) 会发生非自愿的上下文切换,而我们通常感兴趣的阻塞事件是 TASK_INTERRUPTIBLE (1) 或 TASK_UNINTERRUPTIBLE (2),offcputime 可以使用 --state 匹配它们。我在我的Linux 负载平均值:解决谜团帖子中使用了此功能。
火焰图
火焰图是分析堆栈跟踪的可视化,对于快速理解可通过非 CPU 分析生成的数百页堆栈跟踪输出非常有用。张一春首先使用SystemTap创建了CPU外的时间火焰图。
offcputime 工具有一个 -f 选项,用于以“折叠格式”发出堆栈跟踪:分号分隔在一行上,后跟指标。这是我的FlameGraph软件作为输入的格式。
例如,为 mysqld 创建一个 CPU 外火焰图:
# /usr/share/bcc/tools/offcputime -df -p `pgrep -nx mysqld` 30 > out.stacks
[...copy out.stacks to your local system if desired...]
# git clone https://github.com/brendangregg/FlameGraph
# cd FlameGraph
# ./flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us < out.stacks > out.svg
然后在 Web 浏览器中打开.svg。它看起来像这样(SVG,PNG):
好多了:这显示了所有 CPU 外堆栈跟踪,y 轴上的堆栈深度,宽度对应于每个堆栈中的总时间。从左到右的顺序没有任何意义。内核和用户堆栈之间有分隔符帧“-”,由 offcpputime 的 -d 选项插入。
您可以单击以缩放。例如,单击右下角的“do_command(THD*)”帧,以放大查询期间发生的阻塞路径。您可能希望生成仅显示这些路径的火焰图,这些路径可以像 grep 一样简单,因为折叠格式是每个堆栈一行:
# grep do_command < out.stacks | ./flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us > out.svg
生成的火焰图(SVG,PNG):
这看起来很棒。
有关 CPU 外火焰图的更多信息,请参阅我的CPU 外火焰图页面。
唤醒
现在您已经知道如何执行 CPU 外跟踪并生成火焰图,您开始真正查看这些火焰图并解释它们。您可能会发现许多 CPU 外堆栈显示阻塞路径,但未显示阻塞路径的完整原因。该原因和代码路径与另一个线程有关,该线程在阻塞的线程上调用唤醒。这种情况一直在发生。
我在CPU 外火焰图页面中介绍了这个主题,以及两个工具:唤醒时间和关闭唤醒时间,用于测量唤醒堆栈并将它们与 CPU 外堆栈相关联。
其他操作系统
- Solaris:DTrace 可用于 CPU 外跟踪。这是我的原始页面:Solaris Off-CPU Analysis。
- FreeBSD:可以使用 procstat -ka 进行内核堆栈采样,使用 DTrace 进行用户和内核堆栈跟踪来执行 CPU 外分析。我为此创建了一个单独的页面:FreeBSD Off-CPU Analysis。
起源
大约在 2005 年,在探索了 DTrace 调度提供程序及其 sched:::off-cpu 探测器的用途之后,我开始使用这种方法。我称它为 off-CPU 分析和指标 off-CPU 时间,以 DTrace 探测器名称命名(不是一个完美的名字:2005 年在阿德莱德教授 DTrace 课程时,一位 Sun 工程师说我不应该称它为 off-CPU,因为 CPU 不是“关闭”的)。《Solaris 动态跟踪指南》提供了一些示例,用于测量某些特定情况和进程状态从 sched:::off-cpu 到 sched:::on-cpu 的时间。我没有筛选进程状态,而是捕获了所有 CPU 外事件,并包含堆栈跟踪来解释原因。我认为这种方法是显而易见的,所以我怀疑我是第一个这样做的人,但我似乎是唯一一个真正推广这种方法的人。我在 2007 年的DTracing Off-CPU Time 以及后来的帖子和演讲中写过它。
总结
CPU 外分析是查找线程阻塞并等待其他事件的延迟类型的有效方法。通过从上下文切换线程的内核调度程序函数中跟踪这一点,可以以相同的方式分析所有 CPU 外延迟类型,而无需跟踪多个源。要查看 off-CPU 事件的上下文以了解其发生原因,可以检查用户和内核堆栈回溯跟踪。
通过 CPU 分析和 CPU 外分析,您可以全面了解线程花费时间的位置。这些是互补的技术。
有关 CPU 外分析的详细信息,请参阅CPU 外火焰图和热/冷焰图中的可视化效果。
更新
我关于 CPU 外分析的第一篇文章是在 2007 年:DTracing Off-CPU Time。
2012年更新:
- 我在USENIX LISA 2012演讲中将 CPU 外分析作为堆栈配置文件方法的一部分。堆栈配置文件方法是收集 CPU 和非 CPU 堆栈的技术,用于研究线程花费的所有时间。
2013年更新:
- 张一春使用 SystemTap 创建了 CPU 外火焰图,并介绍了CPU 外时间火焰图(PDF)。
- 我在 USENIX LISA 2013 演讲中使用火焰图的炽热性能中加入了 CPU 外火焰图。
2015年更新:
- 我发布了FreeBSD Off-CPU Flame Graphs来探索 procstat -ka off-CPU 采样方法。
- 我发布了Linux perf_events Off-CPU Time Flame Graph来展示如何使用 perf 事件日志记录创建这些 - 如果你只有 perf(改用 eBPF)。
2016年更新:
- 我发布了Linux eBPFOff-CPU Flame Graph来展示它的价值,并帮助在eBPF中建立堆栈跟踪(我不得不破解它们以进行概念验证)。
- 我发布了Linux 唤醒和关闭唤醒分析来显示唤醒堆栈分析。
- 我发布了谁在唤醒唤醒者?(Linux链图原型作为走一连串唤醒的概念证明。
- 我在Facebook Performance@Scale演讲开始时描述了CPU外分析的重要性:Linux BPF Superpowers(幻灯片)。
2017年更新:
- 我在我的Linux 负载平均值:解决谜团帖子中使用了一些 CPU 外火焰图。
- 我在 USENIX ATC 2017 关于 Flame Graphs:youtube,slides 的演讲中总结了 CPU、唤醒、唤醒和链图。
