
背景
收到一生产环境报警消息,一个集群的CPU利用率直接飙升到了100%
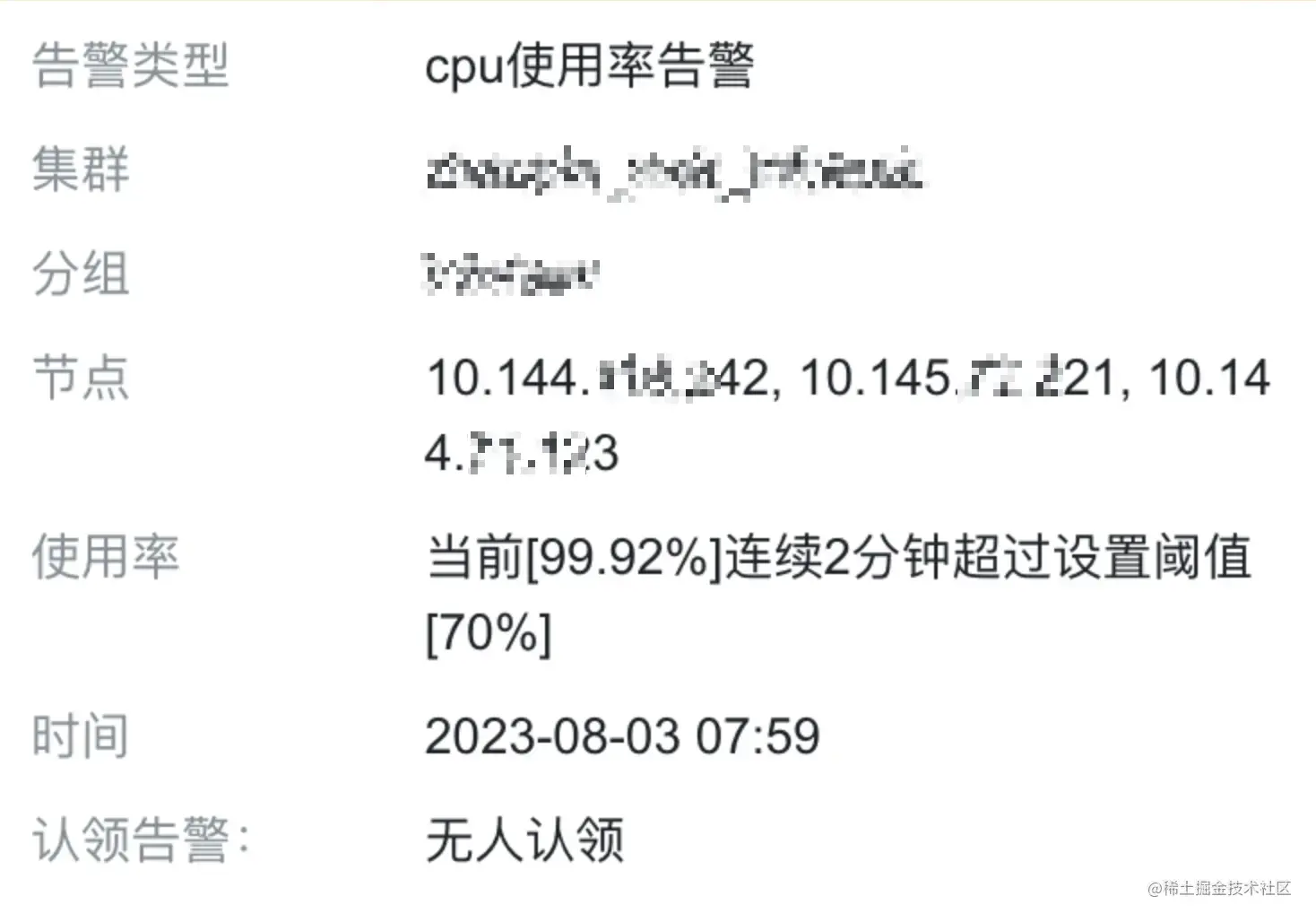
领导说让我处理,但是我还不知道这个集群是干啥用的。。

找问题
看监控
先看下监控看下能不能看到有什么发现,发现这个集群消费MQ消息的数量突增,有几个尖刺状的流量已经达到了每分钟8W+,
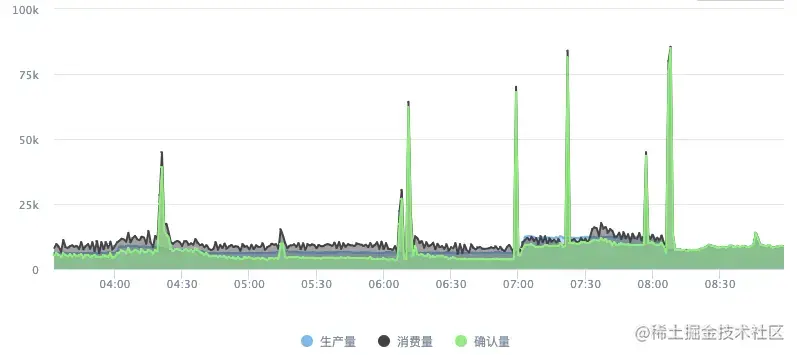
很有可能是尖刺流量造成的这个问题,但是在8:30之后流量已经趋于缓和,但是CPU还是一直100%并没有降下去。
查看jvmGC状况
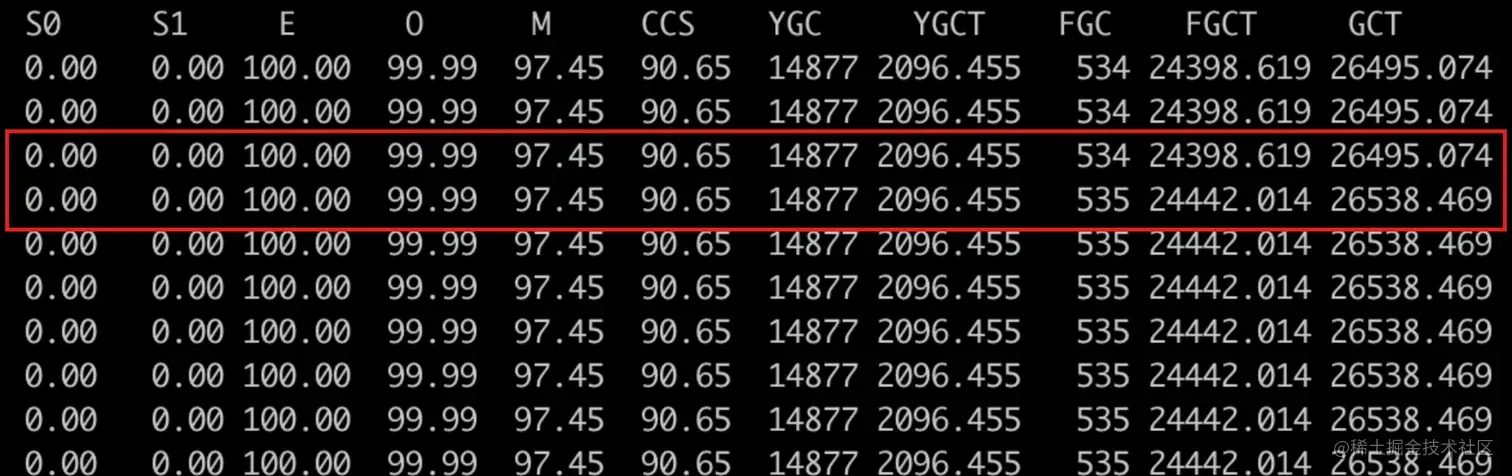
于是登录服务器看下jvm的运行状况。 通过 jstat -gcutil命令查看服务的GC情况,发现已经进行了500多次的FullGC。 关键点在于图中的 534 -> 535次的FullGC内存一点都没有被回收下去,这就很可怕了。
arthas查看服务整体状态
于是想用arthas查看下是否是内存分配有问题到这的内存无法回收,

如图:发现jvm的非堆内存的利用率已经满了,那么很有可能是这个问题导致的。 于是想办法调整下这个内存的大小,打开项目中配置的启动命令发现已经设置了非堆内存的大小,但是这里并没有生效 nohup java -Xms2g -Xmx2g -Xmn1g -Xss1024K -XX:PermSize=512m -XX:MaxPermSize=512m 启动参数长这个样子,其中 -XX:PermSize=512m就是设置非堆内存大小的。但是没有生效。。。。 为什么没生效呢???
jdk7->jdk8内存结构的调整
我们都知道7到8的改动很大,其中一块改动就是jdk8将以前的永久代。 也就是说**_-XX:PermSize_**这个参数在jdk8中已经没有用了,但是这个陈旧的项目并没有人去修改这个参数。 先调整下这个参数试试。 关于永久代和元空间的介绍:
www.cnblogs.com/paddix/p/53…
cloud.tencent.com/developer/a…
分析堆内存
内存无法回收一般是由内存泄漏,或者有大对象无法回收造成的,虽然上面找到一处问题,但是并不能很好的解释为什么内存无法被回收。 分析下堆内存,
- 使用 jmap -dump:live,format=b,file=heap.hprof 命令将堆内存的快照导出,下载下来。
- 使用 jvisualvmjdk自带的工具分析下内存情况
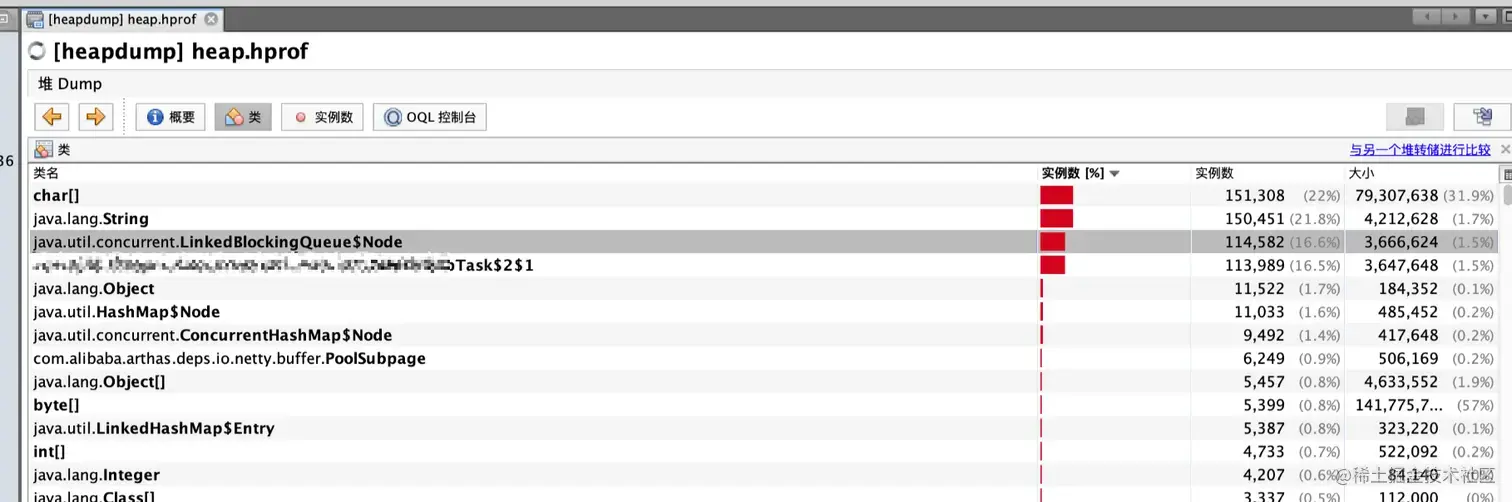
类的分布情况,最大的 cahr[] string这个没什么问题,第三名和第四名就有问题了, 这两个一个是 阻塞队列、一个是业务代码中的一个内部类。 一个内部类怎么会占用这么大的比重,看下代码
java复制代码ExecutorService executorPool = Executors.newFixedThreadPool(numberOfCore);
RateLimiter handleLimit = RateLimiter.create(20, 10, TimeUnit.SECONDS);
ESBClient client = new ESBClient(key_esb);
client.setReceiveSubject(new ESBSubject(INFO_DEL_SUBJECTID, INFO_DEL_CLIENTID,SubMode.PULL));
client.setReceiveHandler(new ESBReceiveHandler() {
@Override
public void messageReceived(final ESBMessage msg) {
try {
final String msgStr = new String(msg.getBody(), "UTF8");
executorPool.execute(new Runnable(){
public void run() {
try {
handleLimit.acquire();
handleDelMsg(msgStr);
} catch (Exception e) {
e.printStackTrace();
}
}
});
} catch (Exception e) {
}
}
});
大家一起看下这端代码有没有什么问题,
- 第一点,这里使用了一个一定不能使用的线程池创建方法,Executors.newFixedThreadPool这个方法创建出来的线程池里面的任务队列是个无界队列。
- 第二点这里用到了限流,RateLimiter这里应该是防止流量过大下游扛不住。
但是为什么要在任务里面限流呢?在线程任务里面限流这个任务放到线程池中,线程在执行任务的时候就会等待 拖慢了整个线程池的运行速度,并发量高的时候大量的任务被放到队列中,而队列又是个无界队列 一下就会把jvm的内存打满,并且这些任务都是被线程池引用的状态无法回收。 这样jvm就会一直进行GC,已经在队列中的任务拿不到CPU资源无法执行,GC又无法回收内存导致了整个集群挂掉。
问题修改
除了修改元空间的启动参数,这里还需要修改代码如下
java复制代码private static final ExecutorService executorPool = new ThreadPoolExecutor(numberOfCore, numberOfCore * 2, 10, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1024), new DefaultThreadFactory("custom"), new ThreadPoolExecutor.CallerRunsPolicy());
RateLimiter handleLimit = RateLimiter.create(20, 10, TimeUnit.SECONDS);
ESBClient client = new ESBClient(key_esb);
client.setReceiveSubject(new ESBSubject(INFO_DEL_SUBJECTID, INFO_DEL_CLIENTID,SubMode.PULL));
client.setReceiveHandler(new ESBReceiveHandler() {
@Override
public void messageReceived(final ESBMessage msg) {
try {
handleLimit.acquire();
final String msgStr = new String(msg.getBody(), "UTF8");
executorPool.execute(new Runnable(){
public void run() {
try {
handleDelMsg(msgStr);
} catch (Exception e) {
e.printStackTrace();
}
}
});
} catch (Exception e) {
}
}
});
- 首先将限流器移到提交任务的时候限流。
- 修改线程池的参数,有界队列、当队列满了调用者执行任务。由于我们这里消费MQ使用的是PULL模式,所有当任务消费不过来的时候就不会去拉消息了,所以采用这个 CallerRunsPolicy策略
后续关注
内存和GC恢复正常


